
Find polls with the help of LLMS
During election cycles, journalists are inundated with data from surveys asking Americans who they plan to vote for and, perhaps more importantly, how they feel about the issues at stake.
Given the sheer volume of polls and the myriad formats in which pollsters release them, it is challenging for newsrooms to keep up and for journalists to know which polls to reference.
PollFinder.ai leverages large language models to help newsrooms collect and organize both horserace and issue polls, enabling journalists to write stories that are informed by an up-to-date aggregation of public opinion polls. This provides a more complete picture of what Americans think about a given topic.
Sign Up to Receive Updates Access Application
Our Plan
Researchers dedicate significant time to identifying which articles contain previously unseen data and processing it appropriately. Many pollsters release polls in unstructured text formats, such as press releases or PDFs, which are then manually entered into a database. This project aims to use LLMs to automate much of the data collection process by extracting structured data from unstructured formats. Here is what we plan to build:
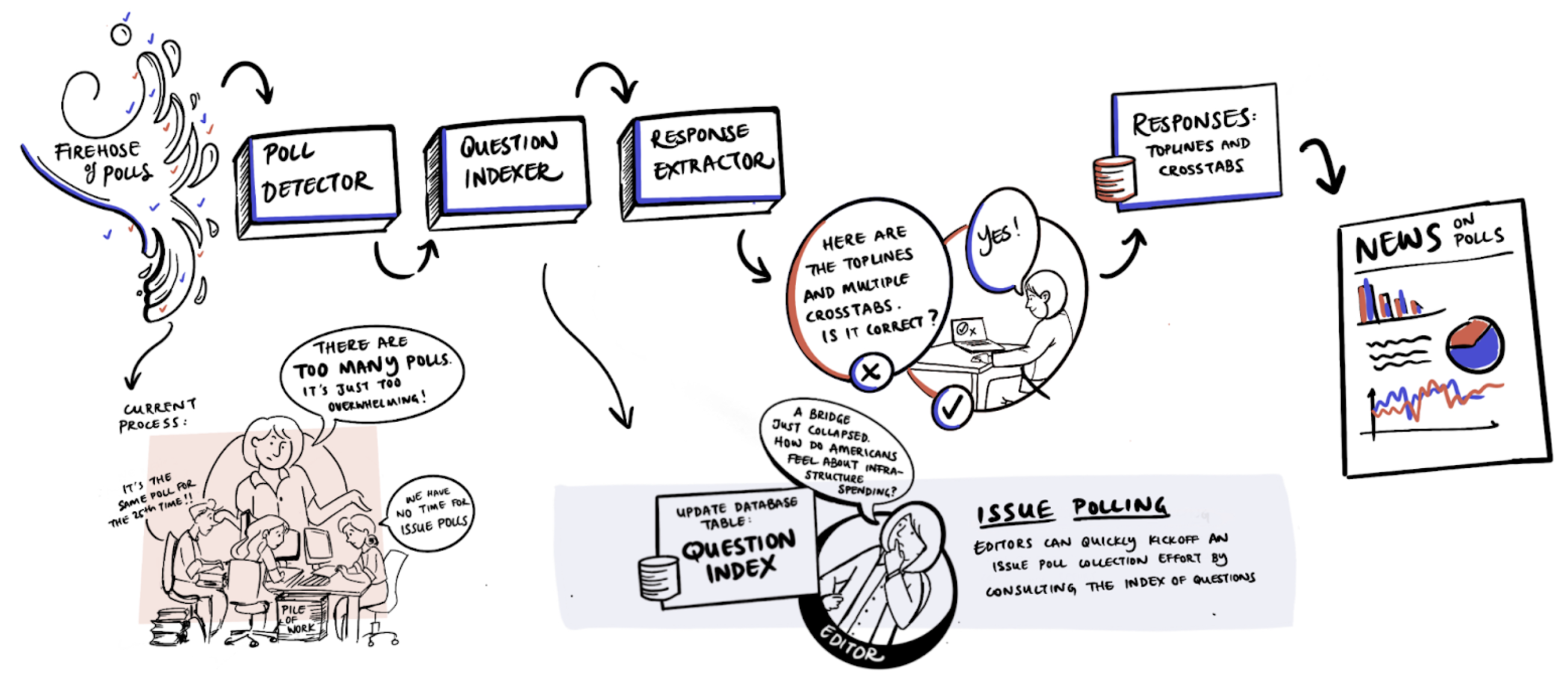
Poll Detector
The Poll Detector extracts metadata such as start date, end date, pollster, and sample size. This helps identify if each item in the firehose of data is a new poll or simply coverage of a poll that has already been collected. This component alone can save valuable time spent on rote data-entry tasks and reduce burnout and staffing issues during elections.
Question Indexer
The Question Indexer extracts and indexes the text of the questions asked in each poll. This machine-readable index of questions enables aggregators to create robust data feeds containing detailed issue polling for journalists to use in their stories.
Response Extractor
The Response Extractor extracts topline and crosstab numbers. This ensures that the resulting data is timely, useful, and searchable, providing aggregators, journalists, and the public with easy access to comprehensive poll data.
Our Team
The Brown Institute for Media Innovation awards “Magic Grants” to projects that bridge the two disciplines, creating new forms of media and ways to serve the public interest. PollFinder received a Magic “Seed” Grant to fund the first iteration of this project, in collaboration with the Brown Institute and Columbia Journalism School.
Dhrumil Mehta
Dhrumil Mehta is an Associate Professor in Data Journalism, Deputy Director of the Tow Center for Digital Journalism, and Visiting Associate Professor in Public Policy at the Harvard Kennedy School. Formerly at FiveThirtyEight, he has illuminated American attitudes on key issues through data-driven journalism.
Aisvarya Chandrasekar
Aisvarya Chandrasekar is a research assistant at Columbia University working on projects at the intersection of data analysis and storytelling. She received her training in data and graphics journalism through the Lede Program at Columbia Journalism School and her undergrad in Electrical Engineering from Rutgers University.
Ken Miura
Ken is a current MS candidate in Computer Science at Columbia University, where he combines his passion for technology and journalism as a researcher at the Tow Center for Digital Journalism. Prior to this, Ken honed his skills in communication and editorial work as a translator and editor for Japanese news outlets. With a diverse background in media and technology, Ken is dedicated to exploring the intersection of digital innovation and journalistic integrity.